In this post we will explore some basic concepts while working with a microservices architecture in a distributed application. If you are not very familiar with microservices and the motivation behind it, you should take a look at this series of posts from NGINX that gives a great introduction on the subject.
All the concepts are quite simple and although the autor had sugested a few things to get started I will take you through the construction of a simple microservices app that you could deploy anywhere.
Warning
This is a simple introduction and will help you get started with the microservices architecture, and hopefully , with Docker. This series of posts are focused towards beginners and enthusiasts
Architecture
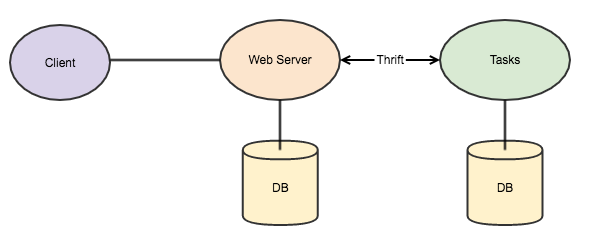
In this simple app we will split it in three simple parts:
- Client - WebUI that will be responsible to create an interface for the final user
- WebServer - API Gateway - Will be responsible for authentication and authorisation, simple data validation and forwarding the requests to other services, if necessery.
- Tasks - A service responsible only to store and manage tasks
In this series we will start from the Tasks service. After we have it ready we will work on our API Gateway and later on we will build an interface for the user.
Tasks service
This is a service that will not be reachable from the outside of our network. It is only responsible to store and manage Task related data. One of the biggest advantages of the microservices architecture is that each service can be implemented with different programming languages. Although, in your team, you will want to keep it to the languages that everybody knows, you could still take advantage of using different languages to solve different things.
For this service I picked Python and Thrift as the RPC. I will not explain the details of Thrift and why I picked it, and focus more in the implementation, so I suggest you take your time to check some articles about it, or other related RPC technologies, like gRPC.
If you prefer to use other language to develop this service, feel free to convert the python syntax to you language of choice. As long as Thrift supports it, everything should work almost exactly the same. If you find some trouble because of the difference, I suggest that you hit the Thrift tutorial for more examples in your language. Keep in mind that the thrift examples are not very updated and you may need to explore a try slight differences in the code to get it working.
If you are on a Mac, you can use brew install thrift to download and install the thrift code generator.
Thrift defines its service-client contract API through a thrift file. For our service we will start from there:
// Basic struct that we will use
struct Task {
1: optional string id,
2: string userId,
3: optional string name = "",
4: optional string createdOn,
5: optional bool done
}
// An base exception class
exception BaseException {
1: i32 code,
2: string message
}
// Here is our Tasks service definition. Just like an interface definition
// it will give us the signature of the service. With Thrift you, after processing
// the file
service Tasks {
//List Tasks
list<Task> all(1:string userId),
//Add Task
Task add(1:string userId, 2:string name),
//Update
Task update(1:string taskId, 2:string name, 3:bool done, 4:string userId) throws (1:BaseException ouch)
//Upsert
Task upsert(1:Task task) throws (1:BaseException ouch)
}
Save this content to a tasks.thrift fileo on the root of your repo and use the thrift cli to generate your server stub
thrift --gen py tasks.thrift
This command will generate a gen-py folder with many files in it
.
├── __init__.py
└── tasks
├── Tasks-remote
├── Tasks.py
├── __init__.py
├── constants.py
└── ttypes.py
1 directory, 6 files
When I was developing this service I faced many issues while figuring out how to work with Thrift and use it for real. Here I will make it all simple for you.
I suggest that you start by creating an virtualenv and install the dependencies there. This way you will not polute your computer’s global scope with unecessary dependencies. Here is the requirements.txt
thriftpy
pymongo
In order to have a flexible configuration parameter, we will use a configuration file called config.py
import os
MONGO_HOST = os.environ.get('MONGO_HOST',
os.environ.get('MONGO_PORT_27017_TCP_ADDR',
os.environ.get('MONGODB_PORT_27017_TCP_ADDR', 'localhost')
)
)
MONGO_PORT = os.environ.get('MONGO_PORT',
os.environ.get('MONGO_PORT_27017_TCP_PORT',
os.environ.get('MONGODB_PORT_27017_TCP_PORT', '27017')
)
)
MONGO_DB = os.environ.get('MONGODB_DATABASE', 'tasks-db')
print(MONGO_HOST)
print(MONGO_PORT)
class Config:
@staticmethod
def getTaskDBConfig():
return {
'host': MONGO_HOST,
'port': MONGO_PORT,
'db': MONGO_DB
}
@staticmethod
def getTaskServiceConfig():
return {
'host': '0.0.0.0',
'port': 6001
}
If you took time to read the code you probably noticed the following:
MONGO_HOST = os.environ.get('MONGO_HOST',
os.environ.get('MONGO_PORT_27017_TCP_ADDR',
os.environ.get('MONGODB_PORT_27017_TCP_ADDR', 'localhost')
)
)
MONGO_PORT = os.environ.get('MONGO_PORT',
os.environ.get('MONGO_PORT_27017_TCP_PORT',
os.environ.get('MONGODB_PORT_27017_TCP_PORT', '27017')
)
)
This will be used to setup our connection with the database. If you are familiar with python you will probably noticed that there are a few defaults to this file, and also a few options available for each variable. Once we get to the Docker part this will be much easier to understand.
We will use Pymongo as our Database interface. Here is the code to implement the basics for the database. Save it as db.py:
from pymongo import MongoClient
from bson.objectid import ObjectId
import pymongo
import datetime
from config import Config
import logging
logger = logging.getLogger(__name__)
mongoConfig = Config.getTaskDBConfig()
baseUrl = 'mongodb://{}:{}'.format(mongoConfig['host'], mongoConfig['port'])
logger.debug('--- MONGO URL: {}'.format(baseUrl))
database = mongoConfig['db']
db = MongoClient(baseUrl)
client = db[database]
class TaskDB:
@staticmethod
def all(userId):
return client.tasks.find({"userId": userId}).sort("createdOn", pymongo.DESCENDING)
@staticmethod
def addOne(userId, name):
instance = {"userId": userId, "name": name, "createdOn": datetime.datetime.utcnow(), "done": False}
instance_id = client.tasks.insert_one(instance).inserted_id
instance["_id"] = instance_id
return instance
@staticmethod
def updateOne(id, userId, name=None, done=None):
print('updateOne(%s,%s,%s,%s)' % (id, name, done, userId))
criteria = {"userId": userId, "_id": ObjectId(id)}
update = {}
if (name is not None):
print('setting name as %s' % name)
update['name'] = name
if (done is not None):
print('setting done as %s' % done)
update['done'] = done
result = client.tasks.update_one(criteria, {'$set': update})
instance = None
if (result.matched_count > 0):
instance = client.tasks.find_one(criteria)
return instance
The both files described above will create a simple database manager and a configuration file that you could customize according to your idea. Take note that the DB manager is only connecting at startup and is not managing any connection exceptions or connection failures. This is not good for a production environment, and you should strive to handle failure and reconnect whenever your database connection fails, but this is not the scope of this post so I will leave this for you to change.
With this two classes already implemented, what is missing is just a Thrift interface to start our server and connect with the database. save this as server.py
import thriftpy
tasks = thriftpy.load("./tasks.thrift", module_name="tasks_thrift")
from thriftpy.rpc import make_server
from thriftpy.protocol import TJSONProtocolFactory
import logging
logging.basicConfig()
from db import TaskDB
from config import Config
class TaskHandler(object):
def check(self):
hc = tasks.Healthcheck()
hc.ok = True
hc.message = "OK"
return hc
def all(self, userId):
print('getting all tasks for user: %s' % userId)
cursor = TaskDB.all(userId)
result = []
task = None
for t in cursor:
task = tasks.Task()
task.id = str(t['_id'])
task.name = t['name']
task.createdOn = t['createdOn'].isoformat()
task.userId = t['userId']
task.done = t['done']
result.append(task)
return result
def add(self, userId, name):
print('add(%s,%s)' % (userId, name))
instance = TaskDB.addOne(userId, name)
task = TaskHandler.convertInstance(instance)
return task
def update(self, id, name, done, userId):
print('update(%s, %s, %b, %s)' % (id, name, done, userId))
instance = TaskDB.updateOne(id, name, done, userId)
if (instance == None):
exception = tasks.BaseException()
exception.code = 404
exception.mesage = 'Task not found'
raise exception
task = TaskHandler.convertInstance(instance)
return task
def upsert(self, task):
print('upsert(%s)' % (task))
if (task is None):
exception = tasks.BaseException()
exception.code = 400
exception.message = 'Task data is invalid'
try:
if (task.id is not None):
instance = TaskDB.updateOne(task.id, task.userId, task.name, task.done)
else:
instance = TaskDB.addOne(task.userId, task.name)
except (Exception):
exception = tasks.BaseException()
exception.code = 400
exception.message = 'Unkown error'
raise exception
print(instance)
if (instance is None):
exception = tasks.BaseException()
exception.code = 404
exception.message = 'Task not found'
raise exception
task = TaskHandler.convertInstance(instance)
return task
@staticmethod
def convertInstance(instance):
task = tasks.Task()
task.id = str(instance['_id'])
task.userId = instance['userId']
task.name = instance['name']
task.createdOn = instance['createdOn'].isoformat()
task.done = instance['done']
return task
host = Config.getTaskServiceConfig()['host']
port = Config.getTaskServiceConfig()['port']
print('Server is running on %s port %d' % (host, port))
server = make_server(tasks.Tasks,
TaskHandler(),
host,
port)
server.serve()
You will notice that we finally started to use our thrift generated server skeletton in the first few lines. The TaskHandler class will be the one responsible to receive thrift transported data and implement all the methods declared in our service interface inside our thrift file.
With these files you have a very simple service that will handle our Task related data. To start your server you will need first to install MongoDB and then type python server.py in your terminal. As this is a Thrift service, you will need to implement your client. This is an example client that you can use for testing.
import thriftpy
tasks_thrift = thriftpy.load("tasks.thrift", module_name="tasks_thrift")
from thriftpy.rpc import make_client
client = make_client(tasks_thrift.Tasks, '127.0.0.1', 6000)
# Add a task
client.add('userid','name')
list = client.all('userid')
for l in list:
print l
# Add other functions you want to test
# client.update()
Save as client.py and start it in another terminal session python client.py
Now, having all this stuff installed in our computers is not really practical. With time you end up with a computer install with many dependencies and you don’t really use most of them after a while. This is one of the many benefits of using Docker. Go ahead an install it in your machine.
For the purpose of this tutorial I created a simple Dockerfile that bundles our Task service in a docker container. Here it is:
# For now, we can use onbuild kind of image, this is not advised for production
FROM python:2-onbuild
CMD ["python", "./server.py"]
EXPOSE 6001
This is a simple file useful for development. Don’t use this for production. As you learn more and more about Docker, you will understand that each Docker container should be treated as a remote server, and all the production requirements that comes with it like:
- Handling failure
- Logging
- Monitoring
- Handling database connections
If you are familiar with Linux servers and deploying applications in production, you already know how to do all this. Explaining these are out of the context of this post and we might explore in a later post.
Save the Dockerfile as Dockerfile in the root of your repo and type docker build -t tasks . to build your docker image.
Now, you will also want to run your database as a docker container as well, and we will run both of them using docker compose
version: '2'
services:
tasks:
image: tasks
ports:
- 6001
environment:
MONGO_HOST: 'mongo'
depends_on:
- mongo
links:
- mongo
mongo:
image: mongo
Save this file as docker-compose.yml in the root of the repo and now you can launch your service, together with a mongo database, from the root of your repo, using the following command:
docker-compose up
It should be running now in the foreground. If you want it running in the background:
docker-compose up -d
Now, you might notice that your docker container has its own IP address and ports, so you client file will not work if not changed. To easily test your file you can enter your docker container using the following commands
# you will need to list your containers first
docker ps
# grab the name of your tasks container, should be something like tasks_tasks_1
docker exec -it tasks_tasks_1 bash
You will notice that you now are currently inside the container but still you can run your client file from within using
python client.py
This project’s code is available in this github repo
https://github.com/danielfbm/tasks-py
Summary
Altough we didn’t explore much in details, In this post we talked about a few topics:
- Microservices architecture
- Thrift
- Tasks service using MongoDB
- Docker basics
In the next post we will explore:
- API gateway
- REST API
- User authentication
- User signup and login
- Connecting to our Tasks service
Stay tunned.